
Overhauling M&A Deal Advisory: The Strategic Integration of GraphRAG, Synthetic Data, and Agentic Workflows in Investment Banking
GraphRAG, synthetic data clean rooms, and agentic AI workflows are reshaping investment banking deal execution.

Abhishek Upadhyay is Director, AI Transformation at Cantor Fitzgerald and an AI product leader focused on turning complex research into decision-ready insights. His work spans McKinsey, Bloomberg, and BNP Paribas, with patents in AI and quantum computing and publications across Elsevier, IEEE, and Springer Nature.
LinkedInCurated by editors who know that exact market. From crypto infra in the Nordics to aviation marketing.
Join 10,000 executives using Authority to decide what to do next, two steps ahead.
Trusted by investors from
Free. No hidden fees. Cancel anytime.
M&A deals are surging, driven by AI acquisitions. To overcome slow due diligence and legal hurdles, investment banks are shifting to advanced AI:
- GraphRAG for hyper-accurate, auditable due diligence, moving beyond simple Vector RAG.
- Synthetic Data used in secure Data Clean Rooms to legally predict deal synergies before closing.
- Agentic AI is taking over complex workflows, cutting multi-week tasks down to hours.
- The main challenge is that firms need to redesign their underlying workflows, not just buy new software, to get a positive ROI.
In This Report
The Macroeconomic Catalyst for AI-Driven Deal Execution
The global mergers and acquisitions (M&A) landscape has reached a defining inflection point in the 2025-2026 transaction cycle. Following a period of intense macroeconomic stabilization, characterized by normalized interest rates and shifting regulatory frameworks, global deal values have experienced a dramatic resurgence. Market data indicates that aggregate deal value reached approximately $4.8 trillion to $4.9 trillion, representing a 40% to 41% year-over-year increase and marking the second-highest year on record.[1] This recovery, however, is heavily bifurcated; it is a K-shaped market driven predominantly by large, strategic megadeals - specifically those exceeding $1 billion - while mid-market and smaller transactions remain constrained by persistent valuation gaps and execution risks.[3]
A central driver of this megadeal activity is the urgent imperative to acquire and integrate artificial intelligence capabilities. In the technology sector alone, which witnessed $343 billion in deal value, a 14% increase, almost half of all strategic transactions exceeding $500 million involved an AI component, representing a doubling of AI-related deal value compared to the entirety of 2024.[4] However, while AI serves as a primary thesis for corporate acquisitions, the fundamental mechanisms by which investment banks and private equity (PE) sponsors execute these deals remain critically impaired by legacy technical debt.
Despite the influx of capital, the mechanical execution of deal advisory is suffering from severe bottlenecks. Due diligence timelines have expanded significantly, with 56% of large and medium-sized investment banks reporting that average deal closures now require a minimum of six months, often delayed by 1 to 3 additional months due to the sheer volume of unstructured data that must be manually parsed.[7] Furthermore, 40% of boutique investment banks identify incomplete or misleading information as their greatest due diligence hurdle.[7] The industry is constrained by outdated technological infrastructure; enterprise organizations currently allocate an estimated 72% of their total IT budgets - costing the global economy roughly $1.68 trillion annually - merely to maintain aging legacy systems, leaving less than 30% of capital for true innovation.[8]
To survive this compressed, high-stakes environment, financial sponsors and corporate dealmakers are rapidly pivoting toward AI-augmented M&A workflows. Recent industry surveys demonstrate that 86% of organizations have integrated Generative AI (GenAI) into their M&A workflows, with 65% of those adoptions occurring within the past year.[9] Furthermore, 83% of these adopters have invested $1 million or more specifically into AI technologies for their M&A deal teams.[9] The following table, adapting data from the 2025 Deloitte M&A Generative AI Study infographic, illustrates the distribution of these investments across the deal lifecycle.
| M&A Deal Lifecycle Stage | GenAI Adoption Rate (%) | Primary Application Focus |
|---|---|---|
| Strategy & Market Assessment | 40% | Target identification, market scanning, adjacency scoring |
| Target Screening & Due Diligence | 35% | Automated contract review, anomaly detection, risk assessment |
| Valuation & Deal Execution | 32% | Dynamic financial modeling, predictive deal engineering |
| Post-Deal Integration | 32% | Cultural mapping, supply chain consolidation, value tracking |
Table 1: Distribution of GenAI Adoption Across the M&A Lifecycle. Data synthesized from the 2025 Deloitte M&A Generative AI Study Infographic.[9]
Despite these massive capital inflows, the first generation of AI deployments in investment banking - primarily relying on standard Large Language Models (LLMs) and basic Vector Retrieval-Augmented Generation (RAG) - has largely failed to deliver the precision required for complex financial and legal research. To overcome these limitations, technical leaders are spearheading a structural overhaul of deal advisory, transitioning to GraphRAG architectures for absolute due diligence accuracy, and deploying AI-generated synthetic data within secure clean rooms to algorithmically quantify pre-deal synergies.
Sponsored report
V7 is an agentic AI platform for private markets, built to automate the document-heavy workflows funds actually run on. Headquartered in London and New York, V7 Go applies AI agents to entire data rooms, running due diligence, generating investment memos, and turning unstructured data into decision-ready outputs. Every figure is fully traceable to its source, so investment committees can stand behind the work.
V7 is trusted by firms including Hamilton Lane, Yale, Capital Dynamics, and Star Mountain Capital, and is backed by $50 million from leading investors. Sifted, Tech Nation, and Deloitte have recognised V7 as one of Europe’s top high-growth tech companies.
This report is sponsored by V7. Authority retains editorial control over the analysis, expert context, and reporting.
Introducing AI Agents: Examples & Use Cases | V7 Go Keynote
The Structural Failure of Vector-Based Retrieval in Corporate Finance
Since late 2022, the predominant methodology for grounding LLMs in proprietary enterprise data has been Vector RAG. This architecture functions by converting unstructured documents - such as earnings call transcripts, credit agreements, and compliance manuals - into dense numerical embeddings. At query time, the system utilizes Approximate Nearest Neighbor (ANN) algorithms to retrieve the text chunks that exhibit the highest semantic similarity to the user's prompt.[10] While Vector RAG excels at generalized knowledge retrieval and broad document summarization, it possesses fatal architectural flaws when applied to the rigorous, highly structured demands of M&A due diligence.
The core limitation of Vector RAG is its blindness to explicit relationships and logical constraints. Legal contracts and financial models are inherently structured; a single commercial contract connects to multiple clauses, each categorized by specific legal parameters.[11] When an investment banker queries a Vector RAG system for complex, multi-hop reasoning, the system invariably collapses. For instance, consider a compliance director conducting pre-deal due diligence on 500 vendor contracts. The director issues a query: "Identify all contracts that contain a Revenue Sharing clause AND a Non-Compete clause, but DO NOT contain Audit Rights".[11]
A standard Vector RAG pipeline cannot reliably execute this command for several fundamental reasons. First, numerical vectors cannot represent the absence of a relationship, meaning the system cannot process the NOT operator regarding Audit Rights; it will frequently retrieve documents specifically highlighting "Section 12: Audit Rights" simply because the semantic similarity score for the phrase is high.[11] Second, it falls into the AND trap; similarity searches cannot guarantee the intersection of multiple specific conditions within the exact same contractual boundary.[11] Third, Vector RAG cannot perform aggregations or counts across categories, rendering it useless for Key Performance Indicator (KPI) tracking or portfolio-wide exposure assessments.[11] Research consistently demonstrates that vector retrieval accuracy degrades rapidly toward zero as the number of entities within a single query exceeds five.[13]
The GraphRAG Paradigm: Knowledge Graphs as the Retrieval Substrate
To rectify the severe limitations of semantic search, enterprise AI architects are rapidly migrating to Graph Retrieval-Augmented Generation (GraphRAG). Pioneered by Microsoft Research and operationalized by graph database providers such as Neo4j and FalkorDB, GraphRAG replaces the flat vector index with a highly structured, interconnected knowledge graph (KG).[12]
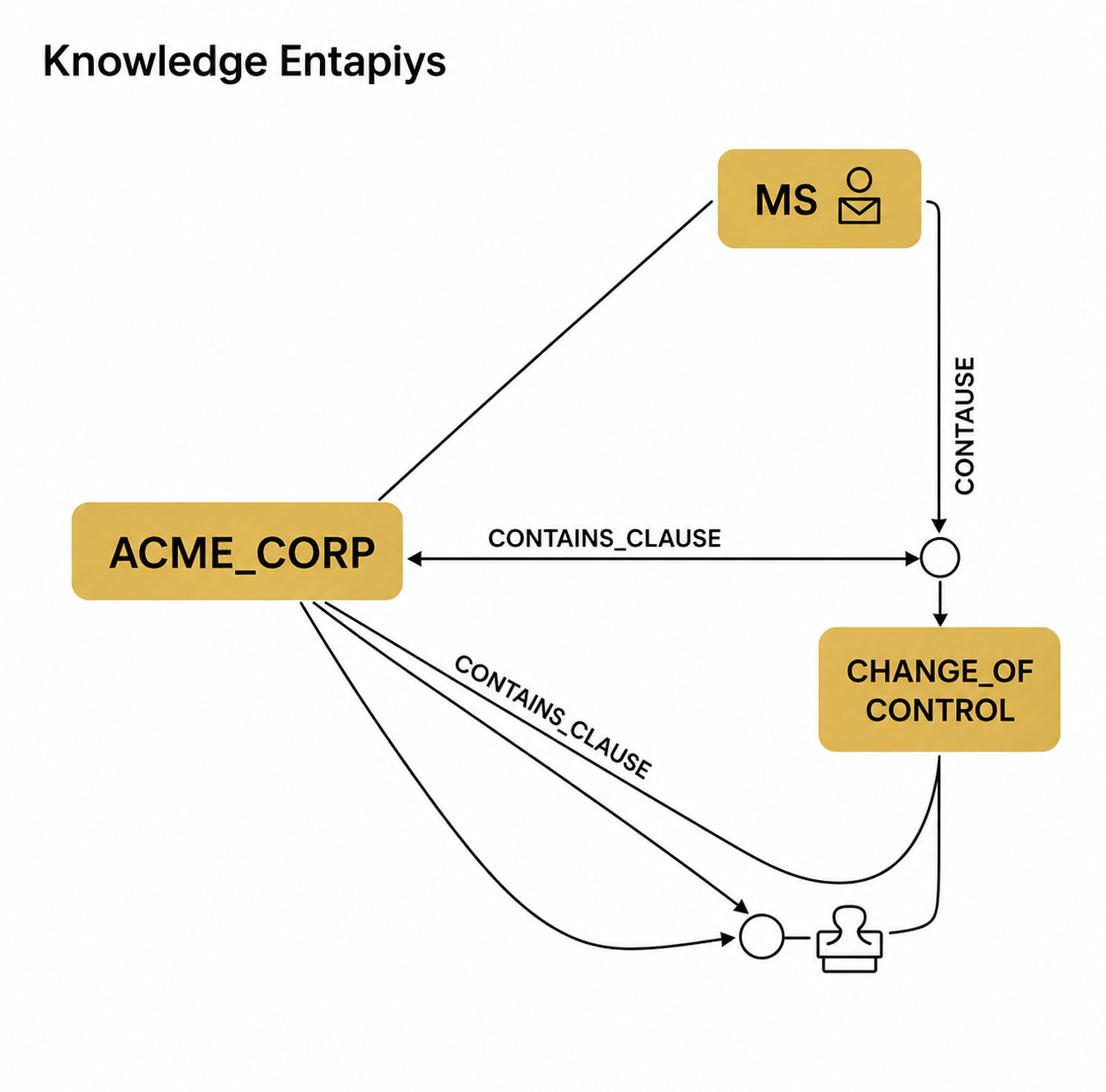
Knowledge Graph
A Knowledge Graph is a data structure that identifies entities, like companies or clauses, from documents and maps the precise, directional relationships between them, like CONTAINS_CLAUSE. This system essentially creates a map of the target company's information ecosystem, enabling the AI to answer complex, multi-step queries with absolute accuracy and a traceable reasoning trail.
Rather than chunking text indiscriminately, GraphRAG utilizes LLMs during the ingestion phase to perform targeted information extraction. The system identifies explicit entities, such as specific corporate entities, named executives, jurisdictions, financial covenants, and legal clauses, and establishes precise, directional relationships between them, such as ACME_CORP CONTAINS_CLAUSE CHANGE_OF_CONTROL.[11] These nodes and edges are then clustered into hierarchical semantic communities, mapping the entire informational ecosystem of a target company.[19]
The runtime architecture of a production-grade GraphRAG system operates across three synchronized layers:[11]
- The Translation Layer: An LLM receives a complex natural language query from a deal analyst and translates it into a deterministic graph database query language, such as Cypher.
- The Retrieval Layer: The underlying graph database executes the Cypher query against the Knowledge Graph, traversing specific relational paths to retrieve factual, interconnected subgraphs rather than probabilistically similar text chunks.
- The Analysis Layer: The LLM receives the retrieved subgraph - representing absolute, schema-aligned facts - and synthesizes a comprehensive business answer, complete with explicit source citations.
This methodology introduces the concept of whole-dataset reasoning. Because the knowledge graph maps the entirety of the target's data room, the AI can traverse multiple degrees of separation to answer complex, exploratory questions.[19] If an analyst asks how a supplier bankruptcy three degrees removed impacts the target's portfolio holdings, GraphRAG seamlessly traces the web of relationships - from the bankrupt supplier, through its corporate parents, across supply chain dependencies, and directly to the target's exposed assets - delivering a comprehensive risk assessment in seconds.[20]
Empirical Benchmarks: Accuracy and Explainability Metrics
The performance disparity between Vector RAG and GraphRAG in financial and legal contexts is stark and measurable. Extensive benchmarking illustrates that while Vector RAG provides satisfactory baseline performance for simple searches, it fails completely on structured analytical tasks. The following table reconstructs the data visualized in recent Diffbot KG-LM and AIMultiple benchmark infographics, detailing the accuracy outcomes across different enterprise query types.
| Query Complexity / Task Type | Vector RAG Accuracy | GraphRAG Accuracy | Performance Delta |
|---|---|---|---|
| Broad Semantic Search (Single Document) | 54.0% | 35.0% | Vector RAG +19.0% |
| Entity Relationship Understanding | ~16.7% | 56.2% | GraphRAG 3.4x improvement |
| Schema-Bound Analytics (KPIs, Forecasts) | 0.0% | >90.0% with advanced SDK | Infinite gain |
| Temporal Reasoning & Multi-hop Paths | 50.0% | 83.0% | GraphRAG +33.0% |
| Cross-Document Reasoning & Aggregation | 8.0% | 33.0% | GraphRAG 4.1x improvement |
Table 2: Comparative Accuracy Benchmarks of Vector RAG vs. GraphRAG in Enterprise Contexts. Data aggregated from Diffbot KG-LM and AIMultiple benchmark analyses.[12]
The most critical advantage GraphRAG offers to investment banks is not merely accuracy, but explainability. In heavily regulated environments - governed by the Bank Secrecy Act (BSA), Anti-Money Laundering (AML) mandates, and the Digital Operational Resilience Act (DORA) - AI deployments must be fully auditable.[24] Vector RAG's reliance on opaque mathematical similarity scores cannot satisfy compliance audits.[10] Conversely, GraphRAG's subgraph-grounded answers produce a native, traceable reasoning trail. Every insight generated is explicitly linked to a node, an edge, and the originating source document, allowing legal and compliance teams to instantly verify the provenance of the AI's output.[10]
An applied study by the international law firm Addleshaw Goddard validates this in a live M&A context. By optimizing a RAG framework for the extraction of key risk clauses across commercial contracts, the firm increased the accuracy of LLM reviews from an out-of-the-box baseline of 74% to 95%, simultaneously compressing review timelines by up to 80%.[27]
Pre-Deal Synergy Quantification: Transitioning from Art to Algorithmic Science
While GraphRAG provides unparalleled precision in identifying liabilities during due diligence, the ultimate success of an M&A transaction is dictated by the accurate projection and realization of deal synergies. Synergy modeling has historically been a highly subjective exercise. Acquirers routinely rely on high-level estimates, treating revenue synergies - the generation of net-new cash flow post-consolidation - as more of an art than a science.[29] Consequently, overestimating revenue synergies remains the most frequently cited reason for deal failure among corporate executives.[29]
To mitigate this risk in the current high-valuation environment, elite acquirers are deploying advanced machine learning models - including Gradient Boosting, Support Vector Machines (SVM), and Deep Neural Networks - to algorithmically predict synergy outcomes. A recent comprehensive study analyzing 10,000 M&A deals executed between 2010 and 2023 demonstrated that an AI-based hybrid machine learning model achieved an Area Under the Precision-Recall Curve (AUC-PR) of 0.912 and an Area Under the Receiver Operating Characteristic Curve (AUC-ROC) of 0.937.[31] This algorithmic approach correctly identified successful synergistic combinations with a 47% higher post-merger integration success rate than traditional target selection methodologies.[31]
These models ingest historical M&A data, financial records, and real-time market trends to map complex, non-linear relationships between variables.[32] The mathematical framework for synergy modeling in an AI context heavily modifies the traditional Discounted Cash Flow (DCF) paradigm. The total synergistic value of a combined entity is quantified by integrating cost synergies, revenue synergies, and the expanded real options value unlocked by AI capabilities, discounted over the relevant period at the appropriate cost of capital.
However, calculating this equation with extreme precision prior to signing requires the ingestion of massive, highly granular datasets from both the acquiring and target companies - such as customer transaction histories, vendor pricing agreements, and proprietary algorithms. This requirement collides directly with immovable legal constraints.
The Privacy Paradox and Regulatory Roadblocks
During the pre-deal phase, strict global privacy regulations, including the EU's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), explicitly prohibit the sharing of Personally Identifiable Information (PII).[34] Furthermore, antitrust regulations strictly forbid gun jumping - the premature sharing of competitively sensitive operational or pricing data between independent entities before regulatory approval and deal closure are finalized.[36]
Historically, dealmakers navigated this by utilizing highly aggregated, heavily redacted, or anonymized datasets. However, traditional data masking severely distorts data quality, destroying the subtle statistical correlations that machine learning models require to accurately predict synergistic overlap.[35] Moreover, researchers have repeatedly demonstrated that supposedly anonymized datasets can easily be re-identified through cross-referencing, exposing the firms to massive regulatory fines and reputational destruction.[38]
The AI-Generated Synthetic Data Solution
To resolve this privacy paradox, investment banks are leveraging AI-generated synthetic data. Synthetic data is a completely artificial dataset created from scratch by complex algorithms designed to replicate the mathematical patterns, distributions, and characteristics of the original real-world data.[38]
The generation process relies heavily on advanced AI architectures, primarily Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).[40] In a GAN framework, two neural networks - a generator and a discriminator - compete iteratively. The generator creates artificial financial records, while the discriminator evaluates them against the real dataset. This adversarial training continues until the generated data is statistically indistinguishable from the actual records.[41] Agent-Based Modeling is also utilized to simulate interactions between artificial entities, such as consumers and traders, to map realistic market scenarios and create dynamic digital twins of the target company's audience.[41]
Because synthetic data contains zero traces of actual PII, it inherently reduces the risk of re-identification and can operate outside the practical privacy constraints that block raw-data sharing under GDPR and CCPA.[39] According to Gartner, this technology is recognized as a top strategic trend, with estimates suggesting that 60% of large enterprises will leverage synthetic data or differential privacy techniques by the end of 2025.[39] In financial due diligence, this allows M&A analysts to construct predictive models that determine how credit scores correlate with spending patterns, or how a target's customer base overlaps with the acquirer's, without exposing a single real identity.[38]
Orchestrating Secure Collaboration: Pre-Deal Data Clean Rooms
While synthetic data provides the safe mathematical proxy required for modeling, the generation of this data requires temporary access to the underlying raw data of both the buyer and the seller. To facilitate this securely, investment banks employ M&A Data Clean Rooms (DCRs) hosted on enterprise data infrastructure platforms like Snowflake, Databricks, and Amazon Web Services (AWS).[45]
A Data Clean Room is a highly secure, cryptographically isolated environment where multiple parties can collaborate on data without directly exposing their raw, proprietary information to one another.[45] The integration of GenAI and synthetic data capabilities directly into these clean rooms represents a structural evolution in pre-deal advisory, functioning through a meticulous sequence of operations:
- Secure Ingestion and Encryption: Both the acquirer and the target upload their respective proprietary datasets into the clean room ecosystem. Crucially, the data providers retain full governance and control; the data is not physically moved or shared in its raw format.[47]
- Federated Synthetic Generation: Utilizing specific capabilities, such as AWS Clean Rooms ML, the system trains a custom machine learning model on the collective, underlying raw data within the secure enclave. It then generates a privacy-preserving synthetic dataset.[46]
- Rigorous Privacy Verification: Before the synthetic data is released for analysis, the clean room infrastructure mathematically verifies that the generated output meets predefined privacy thresholds, ensuring protection against individual re-identification.[51]
- Agentic Synergy Analytics: Once populated into an ML input channel, approved clean team members - or autonomous AI agents - run complex SQL queries and predictive models against the synthetic dataset.[45]
This architecture acts as a dual layer of protection: the clean room governs cryptographic access, while the synthetic data ensures anonymity.[46] The operational benefits are profound. By analyzing key commercial levers - such as procurement consolidation, geographic customer overlap, and product harmonization - weeks before the transaction officially closes, organizations eliminate the traditional Day 1 integration scramble.[45] Acquirers enter the post-close phase with ready-to-execute, granular integration roadmaps, drastically accelerating the realization of cost and revenue synergies and improving competitive positioning.[37]
The Modern M&A AI Technology Stack and Agentic Workflows
Executing this advanced advisory paradigm requires a fundamental redesign of the investment banking technology stack. AI is no longer a peripheral software-as-a-service (SaaS) application; it must be deeply integrated into the core infrastructure. The modern M&A tech stack is conceptualized across five interdependent layers:[52]
- The Governance Layer: The overarching framework ensuring responsible deployment. This involves automated security protocols, access-control validation, and hallucination monitoring using LLM-as-a-Judge evaluator pipelines.[54]
- The Application Layer (Agentic Orchestration): Moving beyond passive chatbots, this layer relies on autonomous multi-agent orchestration frameworks like LangChain and LangGraph. Specialized agents communicate, delegate subtasks, and execute complex workflows without human hand-holding.[55]
- The Model Layer: Utilizing foundational models for complex reasoning and dynamic Cypher query generation, while increasingly relying on Small Language Models (SLMs) tuned specifically for financial extraction to reduce latency and compute costs.[55]
- The Data & Retrieval Layer: The substrate of the system, comprising Vector databases such as Pinecone and Weaviate for semantic search, Graph databases such as Neo4j and FalkorDB for structured relationship mapping, and Clean Rooms such as Snowflake and AWS for secure collaboration.[54]
- The Infrastructure Layer: The foundational cloud compute, requiring specialized GPU/TPU provisioning to manage the intense workloads of training synthetic data generators and parsing massive data rooms.[54]
The Shift to Agentic Workflows
The true transformative power of this stack is unlocked through Agentic AI. For decades, M&A efficiency meant optimizing human execution. Agentic AI shifts this paradigm by embedding intelligent systems directly into decision rights and operational workflows.[60]
In a traditional due diligence process, an associate must manually log into a virtual data room, download thousands of PDFs, search for specific terms, compile anomalies into an Excel tracker, and draft a memo. In an agentic GraphRAG architecture, this process is federated.[57] A Global Coordinator Agent receives the primary diligence mandate. It spawns a Local GraphRAG Agent to traverse the immediate graph neighborhood of specific high-risk contracts, while simultaneously deploying a Financial Analysis Agent to interface with external APIs, like PitchBook or ChatFin, to pull real-time market comparables.[61] These agents synthesize their findings and present a heavily vetted, hallucination-resistant report, complete with source links, directly to the senior dealmaker.
Firms deploying these agentic systems report unprecedented timeline compression. Complex diligence tasks that previously required eight man-weeks of effort are now systematically completed in a matter of hours, allowing boutique banks to execute with the leverage of massive, multi-tiered analyst benches.[63] The following table highlights the premier enterprise vendors supplying this specific infrastructure for financial services in 2025/2026.
| Vendor / Platform | Layer Category | Core M&A Utility | Specialized Capability |
|---|---|---|---|
| Neo4j / FalkorDB | Data & Retrieval | Knowledge Graph Database | High-performance graph traversal; semantic community clustering.[12] |
| AWS Clean Rooms ML | Infrastructure / Model | Secure Collaboration | Cryptographic federated learning; built-in synthetic data generation.[46] |
| MOSTLY AI | Model / Data | Synthetic Data Generation | SDK integration with Databricks; statistically robust financial digital twins.[35] |
| Sana Agents / Blueflame AI | Application / Agentic | Workflow Orchestration | SOC 2 Type II compliant multi-agent frameworks tailored for private equity and banking.[64] |
| Pigment | Application | Predictive Deal Engineering | Dynamic, AI-assisted financial modeling and scenario valuation.[62] |
| V7 Go | Application / Agentic | Private-markets workflow automation | V7 applies AI agents to entire data rooms, running due diligence, generating investment memos, and turning unstructured data into decision-ready outputs. Every figure is fully traceable to its source, so investment committees can stand behind the work |
Table 3: The Enterprise AI Vendor Landscape for Investment Banking & M&A Deal Advisory. Data aggregated from industry vendor assessments.[56]
The ROI Paradox: Overcoming the Implementation Gap
Despite the profound technological capabilities now available to investment banks, a severe implementation gap exists. According to the BCG Center for CFO Excellence 2025 survey, while belief in AI runs exceptionally high, the median reported Return on Investment (ROI) among finance leaders is just 10% - well below the 20% target many organizations require to justify the capital expenditure.[66] Furthermore, a broader global survey indicates that only 6% of organizations achieved payback on their AI investments within a twelve-month period.[67]
This ROI Paradox stems from a fundamental misallocation of resources. The data reveals that a staggering 93% of enterprise AI budgets are poured directly into technology procurement, cloud infrastructure, and model licensing, leaving a mere 7% allocated for workflow redesign, capability building, and behavioral change management.[67] AI in M&A acts as a powerful force multiplier; if underlying governance, data practices, and integration disciplines are robust, AI dramatically enhances them. However, if legacy processes are broken, simply layering an LLM on top will only magnify the dysfunction.[68]
Strategic Imperatives for AI/Tech Leaders
1. Demand Structural Fidelity via Graph-Native Retrieval
The era of relying on pure vector search for M&A due diligence is over. Vector embeddings are blind to the logical, schema-bound requirements of financial audits and legal contract review.[12] IT leaders must mandate GraphRAG architectures for all high-stakes retrieval systems. By meticulously designing the domain ontology - defining precisely how clauses, companies, and liabilities interrelate - firms can achieve the 95%+ accuracy and absolute explainability required by regulators and deal committees.[10]
2. Institutionalize Synthetic Data for Pre-Deal Synergy Quantification
Eliminate the legal bottleneck of pre-deal data sharing. Firms must partner with platforms like AWS or Snowflake to establish permanent Data Clean Room infrastructure. By leveraging GANs and VAEs to generate mathematically identical, privacy-safe synthetic datasets, acquiring firms can execute deep, predictive synergy modeling, avoiding the overestimation traps that historically destroy post-merger value.[35]
3. Pivot from Copilots to Autonomous Agentic Frameworks
Generative AI must evolve from an assistant into a co-creator of the deal.[69] Tech leaders must architect federated, multi-agent systems where specialized AI agents, such as Financial Analysts, Legal Extractors, and Compliance Evaluators, collaborate to process entire virtual data rooms autonomously.[55] This reallocates human capital away from brute-force document parsing toward strategic judgment, negotiation, and relationship management.[70]
4. Leverage Agents to Bypass Legacy Migration Constraints
Rather than delaying crucial M&A integrations due to the prohibitive cost and risk of merging outdated core banking mainframes, organizations should utilize Agentic AI as an intelligent middleware layer. AI agents can seamlessly extract, map, and consolidate data across disparate, siloed legacy systems on the fly, delivering immediate operational visibility while comprehensive data migrations are executed systematically over the long term.[57]
5. Redesign the System of Work, Not Just the Software
To capture the elusive 20% ROI, leadership must fundamentally restructure the deal lifecycle. The linear process of origination, diligence, valuation, and integration must collapse into parallel, AI-augmented streams. By funding the system of work and heavily investing in the behavioral adoption of these tools by managing directors and analysts alike, firms can realize up to 85% productivity gains in specific diligence tasks and compress overarching deal timelines from months into days.[67]
Conclusion
The convergence of Graph Retrieval-Augmented Generation, AI-generated synthetic data, and Agentic workflows represents the most significant structural overhaul of M&A deal advisory in modern financial history. As global deal values approach $5 trillion and the demand for rapid, flawless execution intensifies, the traditional investment banking model - reliant on massive offshore teams and endless manual document review - is no longer viable.
GraphRAG fundamentally solves the hallucination and reasoning deficits of early generative AI, providing the deterministic, highly explainable intelligence required for rigorous legal and financial due diligence. Simultaneously, the deployment of synthetic data within secure, cryptographic clean rooms circumvents the regulatory paralysis of GDPR and antitrust laws, enabling elite acquirers to transition synergy quantification from an unpredictable art into a precise, algorithmic science. Driven by multi-agent architectures that orchestrate these complex tasks autonomously, dealmakers can now identify hidden risks, forecast robust valuations, and execute post-merger integrations with unprecedented clarity and velocity. For AI and technology leaders within the financial sector, mastering this specific technology stack is the definitive mandate to dominate the next era of global dealmaking.
Works Cited
- M&A Report 2026 - M&A Trends & Outlook - Bain & Company
- M&A in 2025 and Trends for 2026 - Morrison Foerster
- AI's increasing impact on M&A - PwC
- 2025 WilmerHale M&A Report
- M&A in Software: Five Secrets to Creating Real Value When Acquiring AI Assets
- Looking Back at M&A in 2025: Behind the Great Rebound - Bain & Company
- M&A Due Diligence Study: 2025 Insights & Trends - SRS Acquiom
- The AI-Powered Legacy Modernization Playbook - Altimi
- 2025 M&A Generative AI Study - Deloitte US
- Graph RAG vs. Vector RAG: Choosing the Right Architecture for Enterprise Use Cases
- GraphRAG for Legal AI: Why Knowledge Graphs Beat Vector Search
- GraphRAG vs Vector RAG: Accuracy Benchmark Insights - FalkorDB
- GraphRAG vs. Vector RAG: When Knowledge Graphs Outperform Semantic Search - Fluree
- GraphRAG vs. Vector RAG: When Knowledge Graphs Outperform Semantic Search - Fluree
- GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research
- What Is GraphRAG? Architecture, Enterprise Use Cases, and RAG Comparison - Atlan
- Agentic GraphRAG for Commercial Contracts - Neo4j
- What is GraphRAG? - Charter Global
- Unlocking Insights: GraphRAG & Standard RAG in Financial Services
- Agentic GraphRAG for Capital Markets - AWS for Industries
- The Hidden Cost of 98% Accuracy: RAG Architecture Selection
- Graph RAG - AIMultiple
- Graph RAG - AIMultiple
- Maximizing compliance: Integrating gen AI into the financial regulatory framework - IBM
- The Advantages of GraphRAG for Enhanced Regulatory Compliance and Understanding
- Graph-Based Retrieval vs. Vector-Based RAG - msg Rethink Compliance
- The RAG Report - Addleshaw Goddard LLP
- How RAG Is Reshaping Document Review in M&A
- Bringing Science to the Art of Revenue Synergies - Bain & Company
- Synergies in M&A - Wall Street Prep
- AI-Driven M&A Target Selection and Synergy Prediction
- Enhancing M&A Valuation Accuracy
- AI-Driven M&A Target Selection and Synergy Prediction - Open Knowledge Publication
- GDPR, AI and Cybersecurity Considerations in M&A Transactions
- Synthetic Data for Financial Services - MOSTLY AI
- Six Essentials for Achieving Postmerger Synergies - BCG
- Capturing Value from Synergy in PMI - BCG
- Synthetic Data for Financial AI - CDO Magazine
- Syntheticus Case Study SIX
- Synthetic Data For Financial Modeling - Meegle
- AI-Generated Synthetic Data for Financial Modeling: A Double-Edged Sword?
- A Systematic Review of Synthetic Data Generation Techniques Using Generative AI - MDPI
- Digital Twins, Synthetic Data, and Audience Simulations - Verve
- Pre-Training AI Models with Real and Synthetic Data to Improve Model Performance
- How an M&A clean room strategy can accelerate transaction synergies - EY
- How synthetic data and clean rooms are redefining secure data collaboration - IDC
- Snowflake Data Clean Rooms for M&A
- What Is a Data Clean Room? - Snowflake
- AWS Clean Rooms Documentation
- AWS Clean Rooms launches privacy-enhancing synthetic dataset generation
- Considerations for synthetic data generation - AWS Clean Rooms
- The AI Tech Stack
- AI in M&A: Transforming Deal Sourcing, Diligence, and Integration - EthosData
- The AI Tech Stack - Paladin Capital Group
- Blackrock: Agentic AI Architecture for Investment Management Platform - ZenML
- Comprehensive Guide to the RAG Tech Stack - Paragon
- Where is the value of AI in M&A - Deloitte
- Top Generative AI Services Providers in 2025 - Hexaware Technologies
- The Best Pre-Built Enterprise RAG Platforms in 2025 - Firecrawl
- Agentic AI in M&A - Accenture
- AI-Agentic-Workflow-GraphRAG - GitHub
- AI Data Analytics Tools for Investment Banking Professionals - ChatFin
- AI in Investment Banking: Key Trends Shaping Dealmaking in 2026 - Finalis
- The Best AI Solutions for M&A in 2026 - Humanaq
- 7 Best Enterprise AI Agents for Financial Services in 2025 - Sana Labs
- How Finance Leaders Can Get ROI from AI - BCG
- AI awareness and access have skyrocketed, yet real enterprise value and ROI are rare - Deloitte
- AI-Powered M&A: What Bankers Need to Know Now - Spencer Fane
- InfoQ AI, ML and Data Engineering Trends Report - 2025
- Generative AI for Finance - Hebbia
- 10 Wealth Management Trends For 2026 - Oliver Wyman
- Reimagining Investment Banking with AI - McLaren Strategic Solutions
- Best AI Tools for Private Equity Due Diligence - InsightAgent
Methodology
This report synthesizes market reports, benchmark studies, vendor documentation, and practitioner research on GraphRAG, synthetic data, clean rooms, and agentic AI in M&A deal advisory. Citations map to the numbered works-cited section.